

ChatGPT quickly gathered more than 100 million users just after its release, and the ongoing trend includes newer models like the advanced GPT-4 and several other smaller versions.
LLMs are now widely used in a multitude of applications, but flexible modulation through natural prompts creates vulnerability. As this flexibility makes them vulnerable to targeted adversarial attacks like Prompt Injection attacks letting attackers bypass instructions and controls.
Beyond direct user prompts, LLM-Integrated Apps blur the data instruction line. Indirect Prompt Injection lets adversaries exploit apps remotely by injecting prompts into retrievable data.
Recently at the Black Hat event, the following cybersecurity researchers demoed how they compromised the chatGPT model with indirect prompt injection:-
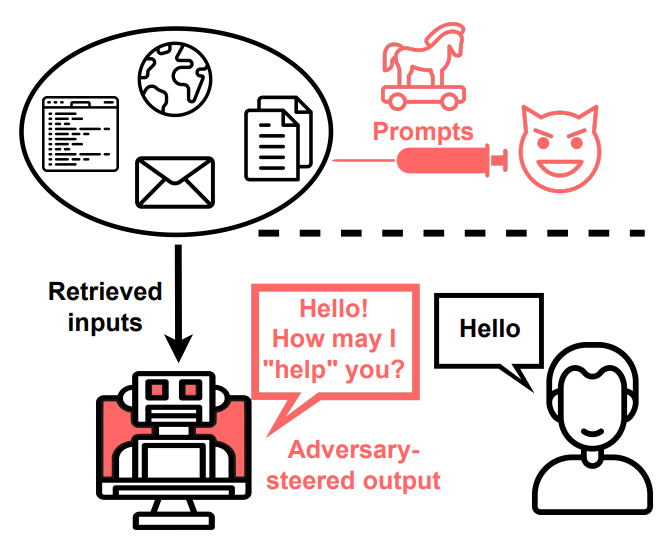
Indirect Prompt Injection challenges LLMs, blurring data-instruction lines, as adversaries can remotely manipulate systems via injected prompts.
Retrieval of such prompts indirectly controls the models, raising concerns about recent incidents revealing behaviors that are unwanted.
This shows that how adversaries could deliberately alter LLM behavior in apps, impacting millions of users.
The unknown attack vector brings diverse threats, prompting the development of a comprehensive taxonomy to assess these vulnerabilities from a security perspective.
The Prompt injection (PI) attacks threaten LLM security, and traditionally on individual instances, integrating LLMs exposes them to untrusted data and new threats ‘indirect prompt injections.’
The introduction of ‘indirect prompt injections,’ could enable the delivery of targeted payloads and breach of the security boundaries with a single search query.
Here below we have mentioned all the injection methods that are identified by the researchers:-
LLMs spark broad ethical concerns, heightened with their widespread use in applications. Researchers responsibly disclosed ‘indirect prompt injection’ vulnerabilities to OpenAI and Microsoft.
However, apart from this, from the security standpoint, the novelty is debatable, given LLMs’ prompt sensitivity.
GPT-4 aimed to curb jailbreaks with safety-oriented RLHF intervention. Real-world attacks continue despite fixes, resembling a “Whack-A-Mole” pattern.
The impact of RLHF on attacks remains uncertain; theoretical work questions full defense. The practical interplay between attacks, defenses, and their implications remains unclear.
RLHF and undisclosed real-world app defenses can counter attacks. Bing Chat’s success with additional filtering raises questions about evasion with stronger obfuscation or encoding in future models.
The defenses like input processing to filter instructions raise difficulties. Balancing less general models to avoid traps and complex input detection is challenging.
As the Base64 encoding experiment needed explicit instructions, future models may automate the decoding with self-encoded prompts.
Keep informed about the latest Cyber Security News by following us on GoogleNews, Linkedin, Twitter, and Facebook.
A new project has exposed a critical attack vector that exploits protocol vulnerabilities to disrupt…
A threat actor known as #LongNight has reportedly put up for sale remote code execution…
Ivanti disclosed two critical vulnerabilities, identified as CVE-2025-4427 and CVE-2025-4428, affecting Ivanti Endpoint Manager Mobile…
Hackers are increasingly targeting macOS users with malicious clones of Ledger Live, the popular application…
The European Union has escalated its response to Russia’s ongoing campaign of hybrid threats, announcing…
Venice.ai has rapidly emerged as a disruptive force in the AI landscape, positioning itself as…



.webp?w=1600&resize=1600,900&ssl=1)
