


Cloudflare experienced a significant service outage that affected several of its key offerings, including R2 object storage, Cache Reserve, Images, Log Delivery, Stream, and Vectorize.
The incident, which lasted 1 hour and 7 minutes, was traced back to a faulty credential rotation process for the R2 Gateway service.
Incident Overview
The outage began at 21:38 UTC and ended at 22:45 UTC. During this time, all write operations to R2 failed, while about 35% of read operations were unsuccessful globally.
.png
)
However, there was no data loss or corruption, as any successful uploads and mutations persisted.
Cloudflare attributed the failure to human error during the credential rotation process, where new credentials were inadvertently deployed to a development instance of the R2 Gateway service instead of the production environment.
Impact on Services
The outage had wide-ranging effects across various Cloudflare services:
- R2: All object write operations failed, and 35% of read operations were unsuccessful. Customers accessing public assets via custom domains saw a reduced error rate due to cached object reads.
- Billing: Customers encountered issues accessing past invoices.
- Cache Reserve: An increase in requests to origins occurred due to failed R2 reads.
- Email Security: Customer-facing metrics were not updated.
- Images: All uploads failed, and image delivery dropped to 25%.
- Key Transparency Auditor: All operations failed during the incident.
- Log Delivery: Log processing was delayed by up to 70 minutes.
- Stream: Uploads failed, and video segment delivery was impacted, causing intermittent stalls.
- Vectorize: Queries and operations on indexes were affected, with all insert and upsert operations failing.
The problem originated when the R2 engineering team omitted the –env parameter during the credential rotation process, inadvertently deploying new credentials to a non-production environment.
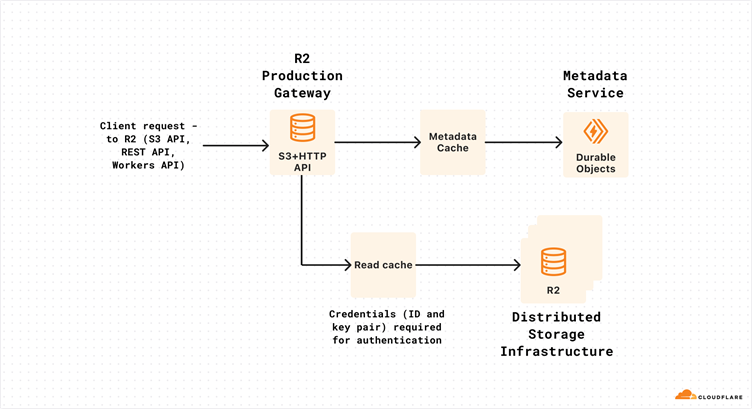
When the old credentials were removed, the production R2 Gateway service lacked access to the new credentials, causing authentication issues with the storage infrastructure.
Resolution and Preventative Measures
Cloudflare quickly resolved the incident by deploying the correct credentials to the production R2 Gateway service. To prevent similar incidents in the future, the company has implemented several changes:
- Enhanced Logging: Added logging tags to track credential usage.
- Process Updates: Mandated explicit confirmation of credential IDs and introduced a requirement for at least two people to validate changes.
- Automated Deployment Tools: Shifted to using hotfix release tooling to reduce human error.
- Improved Monitoring: Upgrading observability platforms to provide clearer insights into endpoint issues.
Cloudflare has expressed deep regret for the disruptions caused and is committed to continuous improvements in resilience and reliability across its services.
This incident highlights the importance of robust process validation and automation in critical system maintenance tasks.
Are you from SOC/DFIR Teams? – Analyse Malware, Phishing Incidents & get live Access with ANY.RUN -> Start Now for Free.

{kind=link}